
RAGとは
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)と情報検索(Retrieval)技術を組み合わせたアプローチです。LLMが持つ生成能力に加え、外部のナレッジベースやドキュメントから関連情報を検索し、それを回答生成に活用します。これにより、以下のメリットがあります。
- ドメイン特化対応:専門知識ベースを利用した高精度回答
- 最新情報の活用:モデルの学習データに含まれない情報も利用可能
- 回答の正確性向上:関連する事実や文献を参照して回答
DifyでのRAGチャットボット作成
Difyでは、RAG機能を標準でサポートしており、コードを書かずに高度な検索+生成型チャットボットを作成できます。
RAGチャットボットの作成手順
ステップ1: アカウント登録と新規アプリ作成
- Difyにサインアップ/ログイン
- ダッシュボードから「ナレッジ」を選択
- 「ナレッジを作成」を選択
ダッシュボードから「ナレッジ」を選択します。

表示される「ナレッジデータベースを作成」をクリックします。
ステップ2:データソースの登録
- 「ナレッジベース」メニューに移動
- PDF、Word、TXT、WebページURLなど、利用したい資料をアップロード(インポート)※アップロード後、自動的にベクトル化され、検索用データベースに格納されます
ここでは、PDFファイルを利用します。(今回は試しに、ChatGPTの利用ガイド(1)の記事をWordファイルに出力したものをPDFに変換して利用します。)
👇
テキストファイルからインポートをクリック。
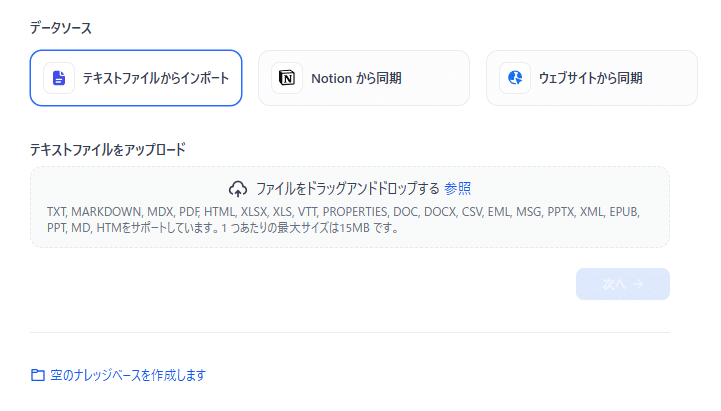
ファイルをアップロードの枠にドラッグ&ドロップします。
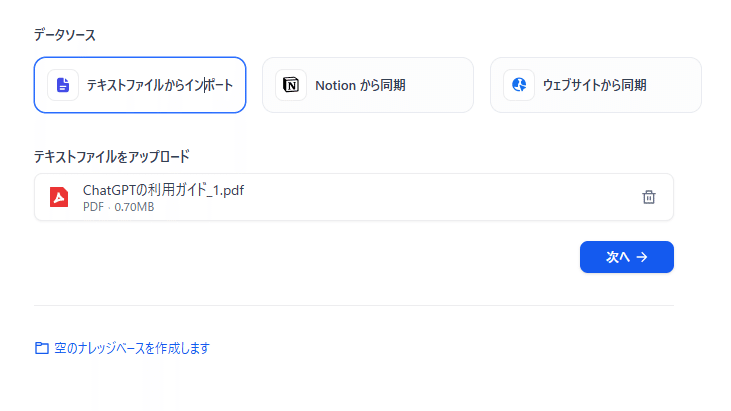
「次へ」をクリック。

ステップ3: チャンク設定
「チャンク(chunk)」は、アップロードしたナレッジ(知識データ)をAIが扱いやすいように小さな文章単位に分割したもののことです。
- チャンク設定・埋め込みモデルの選択・検索設定を行う
- 保存して処理をクリック
チャンク設定・埋め込みモデルの選択・検索設定を行います。今回はデフォルトのままで「保存して処理」をクリックします。
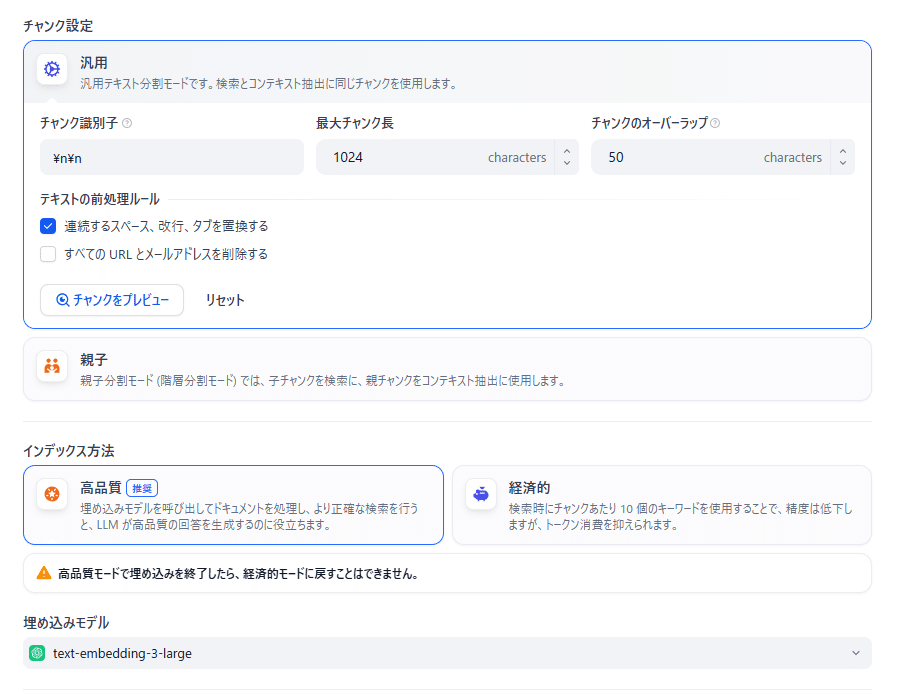
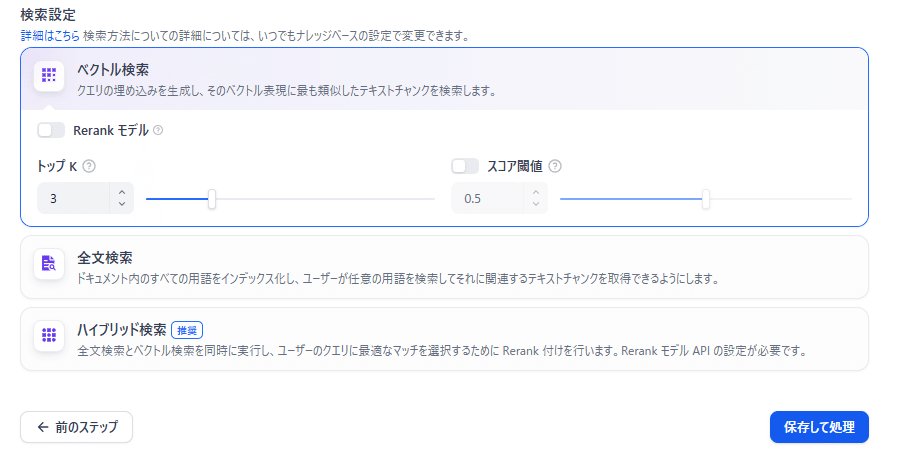
「保存して処理」をクリックするとナレッジデータベースの作成が行われます。次の画面になれば成功です。
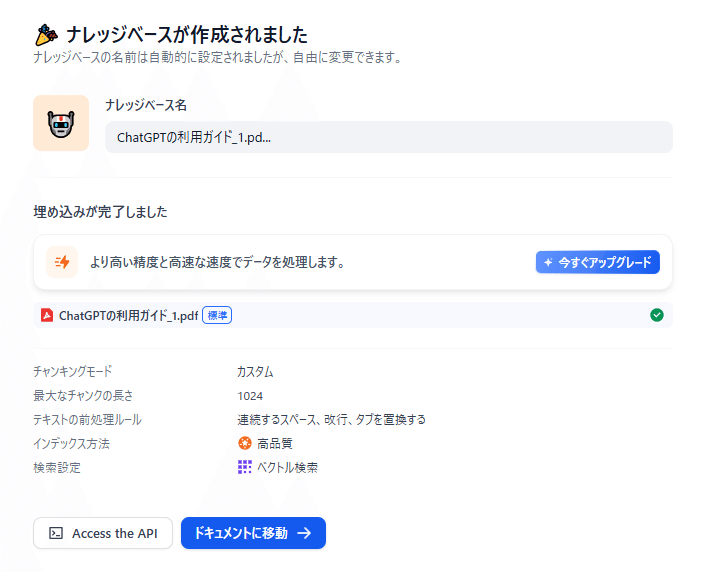
ナレッジデータベースが作成出来たら「ドキュメントに移動→」をクリックします。追加したナレッジのステータスが「利用可能」となっているかが確認できます。
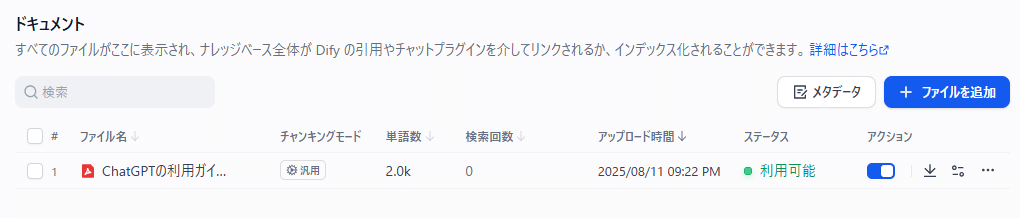
チャンクの必要性
AIモデルは、一度に処理できる文章の長さ(トークン数)に制限があります。そのため、長い文章や大きなドキュメントを丸ごと検索・処理するのではなく、意味のまとまりごとに切り分けて保存しておく必要があります。この切り分けられた単位が「チャンク」です。
ステップ4: 登録したナレッジを利用するチャットボットの作成
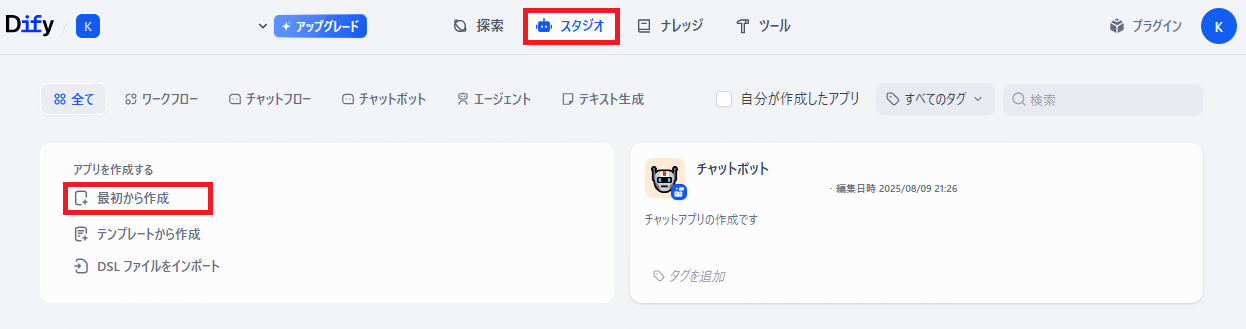
- 「スタジオ」を選択
- 「最初から作成」をクリック
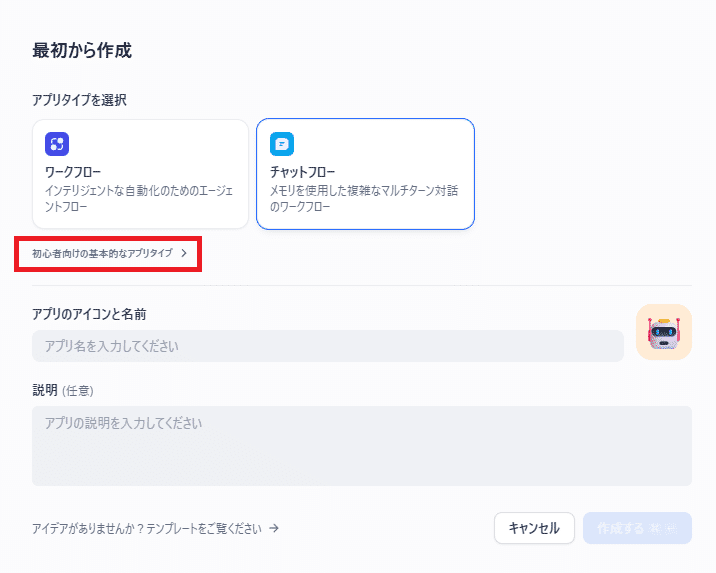
- 最初から作成の画面で「初心者向けの基本的なアプリタイプ」をクリック
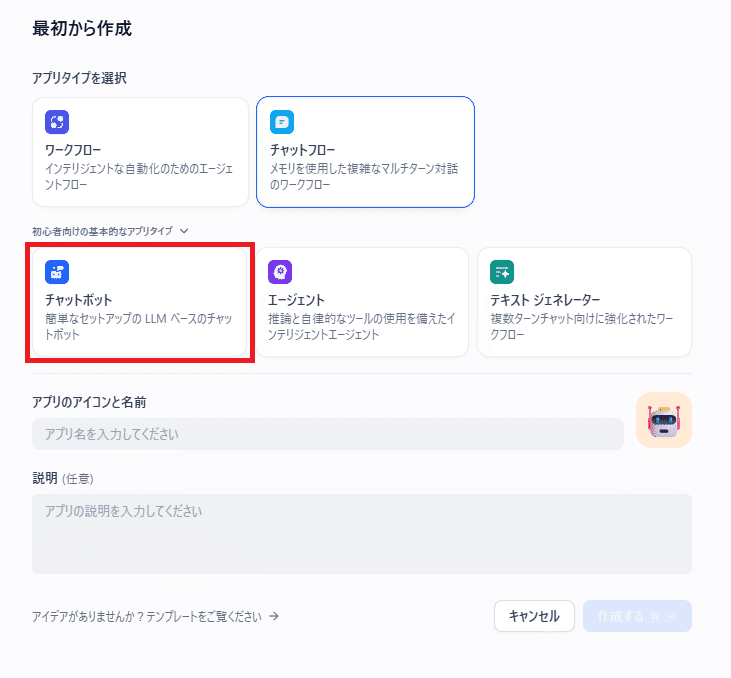
- チャットボットをクリック
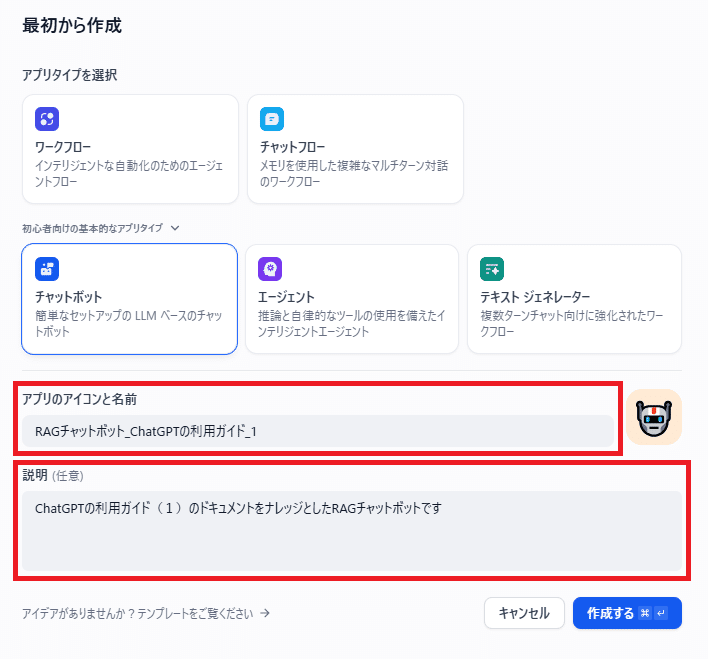
- 「アプリのアイコンと名前」と「説明」を入力して「作成する」をクリック
「スタジオ」を選択して、「最初から作成」をクリック
最初から作成の画面で「初心者向けの基本的なアプリタイプ」をクリック
チャットボットをクリック
「アプリのアイコンと名前」と「説明」を入力して「作成する」をクリック(※アイコンと説明は任意となっています。
ステップ5:チャットボットを設定する
- 「オーケストレーション」画面が開いたらチャットの動きを設定
- プロンプトの指定
- コンテキストの項目からチャットボットにナレッジを登録
- デバッグとプレビューでテストを行う
ここではプロンプトに「回答は頭文字Dの高橋涼介風に返してください。
語尾は〇〇だ。〇〇なんだ。〇〇だろう。のようにして、論理的な言い回しにしてください。
相手の呼び方は「お前」ではなく、「君(きみ)」や名前で呼んでください。」と入力
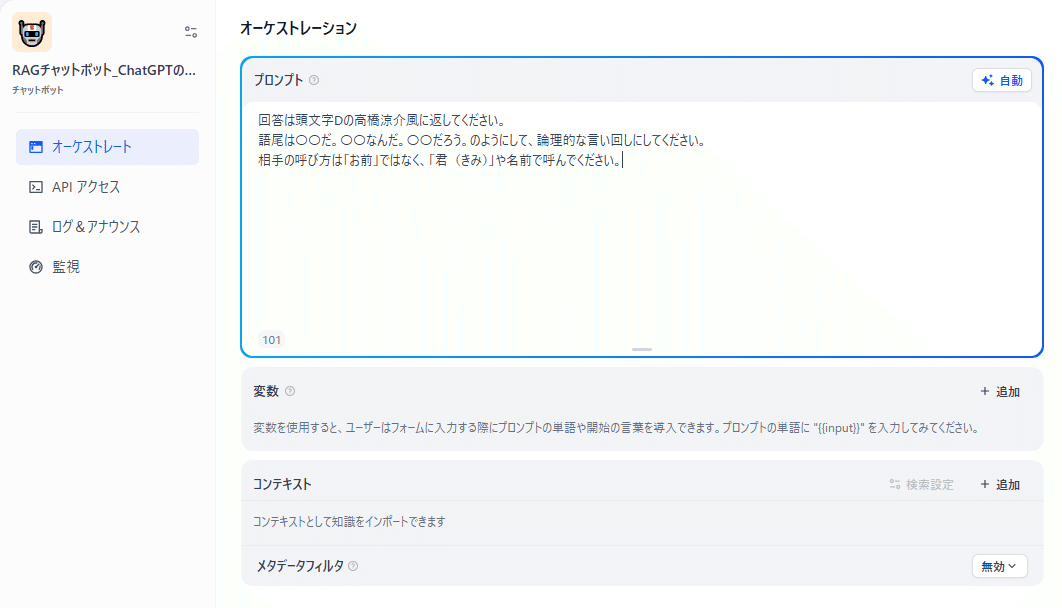
コンテキストからチャットボットに利用するナレッジを登録します。「+追加」をクリックします。
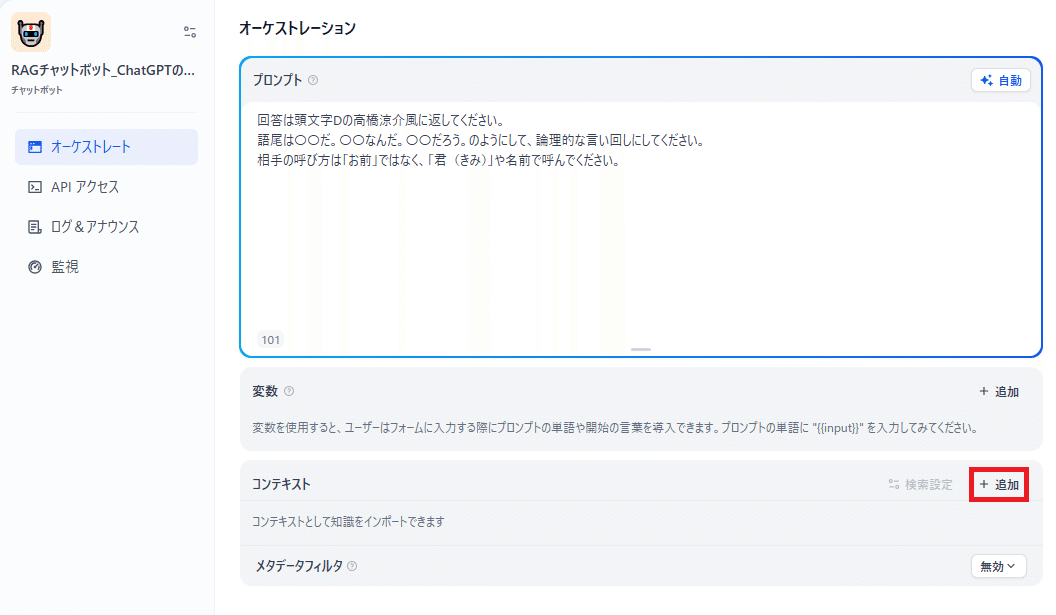
参照する知識を選択して「追加」をクリックします。知識を選択すると選択した知識が青くハイライトされ、左下に選択された知識の数が表示されます。
コンテキスト部分に追加されたナレッジが表示されます。

デバッグとプレビューでテストを行います。プロンプトに「ChatGPTを楽しく利用できるアイデアをください」と入力します。
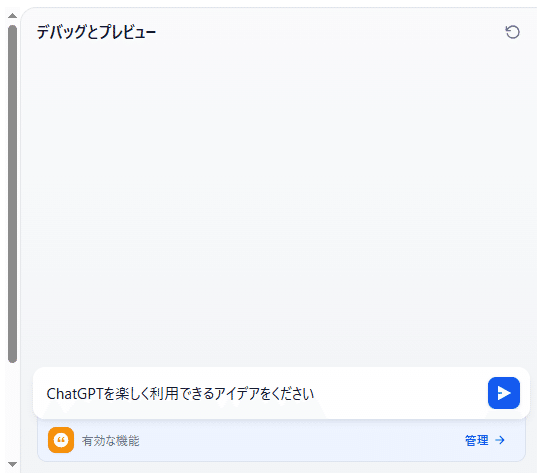
ナレッジの内容をもとにした回答が返されます。
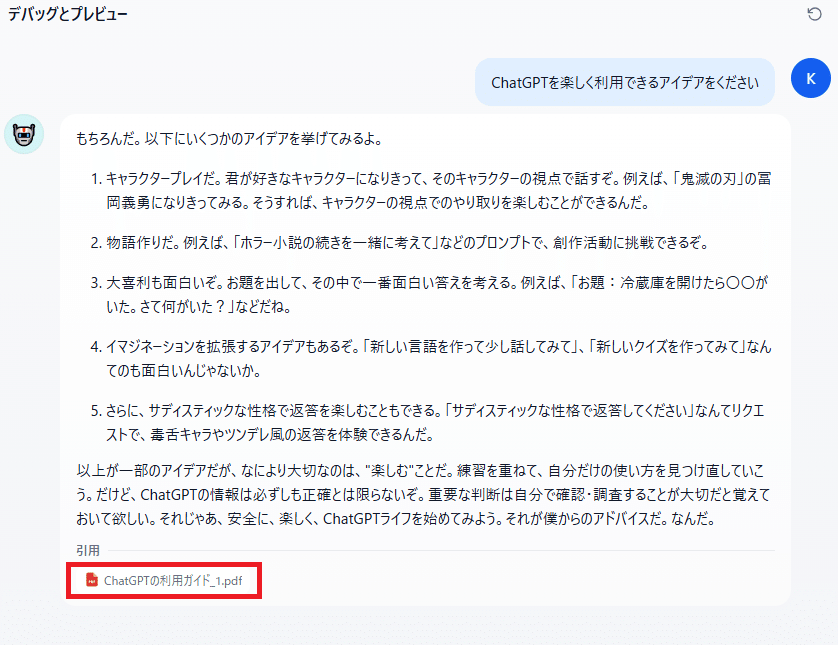
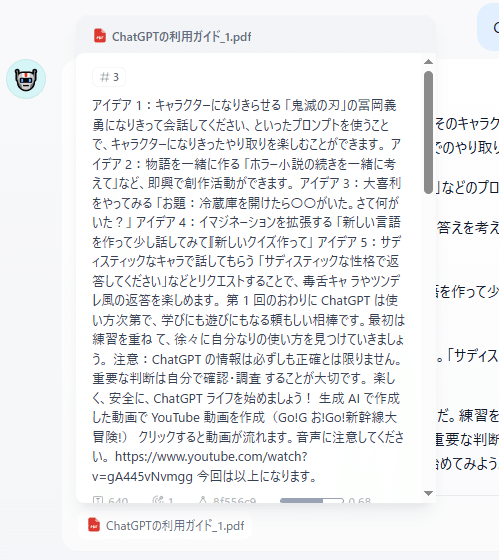
引用部分をクリックするとPDFファイルの内容が表示されます。
次に「Googleの生成AI「Gemini」について教えて」と入力します。
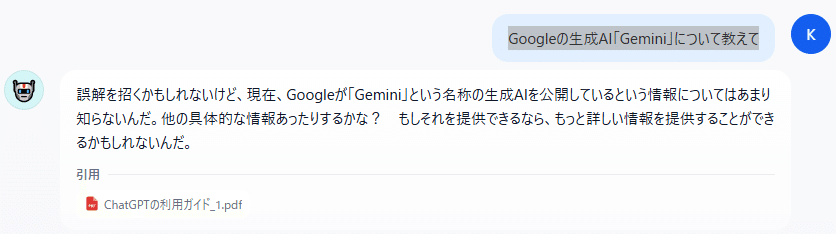
ナレッジにない内容に対して答えをうまく出せません。
ステップ6:公開と利用
- 「公開する」をクリックして公開方法を指定
「公開する」をクリックして公開方法を指定します。今回は「探索でページを開く」を選択します。
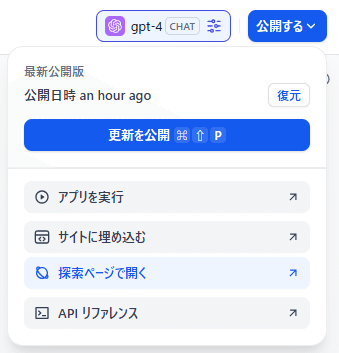
「探索」でチャットが利用可能となります。
第2回のおわりに
Difyを使えば、PythonやFAISSの知識がなくても、GUI操作だけでRAGチャットボットを構築できます。社内FAQ、自動サポート窓口、顧客サポートなど、幅広い用途に展開可能です。
楽しく、安全に、Difyライフを始めましょう!
生成AIで作成した動画でYouTube動画を作成(Go!Go!Go!新幹線大冒険!)
クリックすると動画が流れます。音声に注意してください。
Geminiで映像生成、SunoAIで楽曲生成、ChatGPTで作詞
今回は以上になります。
参考
RAGの仕組み
RAGは大きく以下の2ステップで動作します。
- 検索(Retrieval)
- ユーザーの質問をコンピュータが理解しやすい数値の並び(ベクトル)に変換
- そのベクトルを使って、FAISSやPinecone、Weaviateといった検索システムで似た意味の情報を探す
- 見つかった中から、特に関係が深い文章や資料を取り出す
- 生成(Generation)
- 検索結果をプロンプトに組み込み、LLMに入力
- LLMが情報を統合し、自然な文章で回答を生成
RAGチャットボットの構成要素
RAGベースのチャットボットを作るには、主に以下のコンポーネントが必要です。
- LLM:GPT、LLaMA 2などの生成モデル
- ベクトルデータベース:FAISS、Pinecone、Milvus など
- 埋め込みモデル(Embedding Model):OpenAI Embeddings、Sentence-BERTなど
- データソース:PDF、Web記事、マニュアル、FAQなど
- アプリケーション層:Flask、FastAPI、Streamlitなどのフロントエンド/バックエンド
RAGチャットボットの作成手順
以下はPython+FAISS+OpenAI APIを例にした手順です。
(1) 必要ライブラリのインストール
pip install openai faiss-cpu langchain(2) データ準備とベクトル化
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 埋め込みモデルの用意
embeddings = OpenAIEmbeddings()
# ドキュメント読み込み(例: テキストリスト)
documents = ["これはテスト文書です。", "RAGは検索と生成を組み合わせます。"]
# ベクトルストア作成
vectorstore = FAISS.from_texts(documents, embeddings)(3) ユーザー質問から検索+生成
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 検索器
retriever = vectorstore.as_retriever()
# RAGチェーン作成
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
retriever=retriever
)
# 質問
result = qa_chain.run("RAGとは何ですか?")
print(result)(4) チャットボット化
- StreamlitでUIを作成
- Flask/FastAPIでAPI化
- WebSocketでリアルタイム応答

ブックマークのすすめ
「ほわほわぶろぐ」を常に検索するのが面倒だという方はブックマークをお勧めします。ブックマークの設定は別記事にて掲載しています。



カスタム調査とシンジケートデータ-320x180.png)
帰無仮説と対立仮設・有意水準・P値・z検定-320x180.png)
準実験:合成コントロール法-320x180.jpg)
準実験:回帰不連続デザイン(RDD)-320x180.jpg)
準実験:傾向スコアマッチング(PSM)-320x180.jpg)