データサイエンス(Part.18)|基本統計量
基本統計量-1280x720.jpg)
目標
基本統計量について理解する
基本統計量
基本統計量(descriptive statistics)とは、データの分布を短い数値で要約する指標ことです。「どのあたりに集中しているか(位置)」「どのくらい散らばっているか(ばらつき)」「形はどうか(歪み・尖り)」を手早く把握し、次の分析(相関・回帰・検定)や意思決定の土台にします。標本から計算するため、母集団の性質を推定する推定量としても使われます。
何を「要約」したいのかで、何を利用するかが変わる
- 位置(中心):データの「代表値」(平均・中央値・最頻値 など)
- 散らばり(ばらつき):平均からどれくらい離れているか(分散・標準偏差・IQR など)
- 形(分布の形状):歪みや尖り(歪度・尖度)
- 比率・構成:カテゴリの割合、度数
データの型で使える指標が変わります。
- 名義(カテゴリ)→最頻値・構成比
- 順位→中央値・分位点
- 間隔・比率(連続)→平均・分散・相関…
代表値(位置の尺度)
平均(Arithmetic Mean)
最もよく使う代表値。外れ値に弱い。
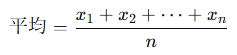
重み付き平均
普通の平均は、すべてのデータを同じ重要度(重み)で扱い、重み付き平均は、各データに 重要度や比率(重み, weight) をつけて平均を計算します。
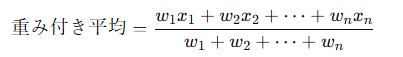
数学 90点(配点50%)、英語 70点(配点30%)、理科 80点(配点20%)
中央値(Median)
データを 小さい順に並べたときの中央の値。外れ値に強いロバストな代表値。
例:データ:2,3,5,8,100
- 平均:23.6(100の影響が大きい)
- 中央値:5(真ん中の値、典型的)
最頻値(Mode)
データの中で 最も多く出現する値で「度数が最大の値」といいます。名義尺度でも利用できます。
例
データ:2,3,3,5,8,8,8,100
- 最頻値:8(3回出現 → 最も多い)
- 中央値:5(並べると真ん中)
- 平均:16.1(外れ値100の影響あり)
幾何平均(Geometric Mean)・調和平均(Harmonic Mean)
幾何平均:n 個のデータ x1,x2,…,xnの幾何平均は:
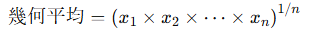
例:ある投資が3年間で「+10%」「+20%」「-10%」の成長率を記録した場合の幾何学平均は次の通りです。
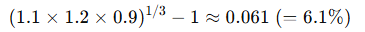
調和平均:n 個のデータ x1,x2,…,xnの調和平均は:
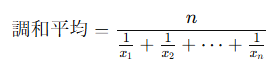
例:車がある距離を「行きは60km/h」「帰りは40km/h」で移動した場合の調和平均は次の通りです。
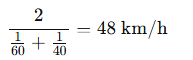
※単純平均だと「50km/h」
切断平均(Trimmed Mean)・Winsor化平均(Winsorized Mean)
切断平均:データを小さい順に並べて、上下の一定割合(または個数)のデータを削除してから算術平均を計算する方法。
例:データ:1,2,3,4,100
10%両側切断平均(上位1個・下位1個を削除) = (2+3+4)/3 = 3
※通常の平均 = (1+2+3+4+100)/5 = 22
Winsor化:データを小さい順に並べて、上下の一定割合(または個数)のデータを削除せずに、境界の値で置き換える方法。
例:データ:1,2,3,4,100
※上位1個(100)を削除せず「4」に置き換える。
※下位1個(1)を「2」に置き換える
→ Winsor化データ = 2,2,3,4,4
Winsor化平均 = (2+2+3+4+4)/5 = 3
ばらつき(散布の尺度)
分散(Variance)「母分散」「標本分散」「不偏分散」
分散:データの「散らばり具合」を表す指標です。平均からどれだけ離れているかを二乗して平均をとります。
母分散:全体からの分散(全てのデータが揃っている)
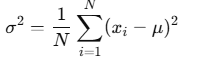
例:母集団データ:2,4,4,4,5,5,7,9
1.母平均の算出
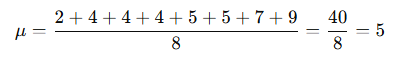
2.偏差の二乗を合計
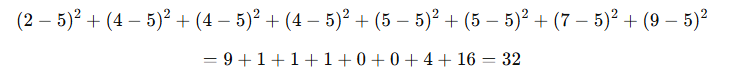
3.母分散の算出
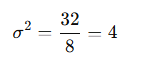
標本分散:サンプルからの推定値
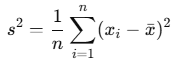
例:母集団データ:2,4,4,4,5,5,7,9(この中からランダムにいくつかを抽出してばらつきを確認する)
1.標本平均の算出
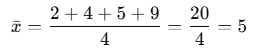
2.偏差平方和
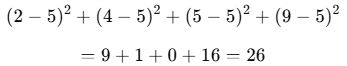
3.標本分散(N=4)
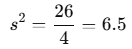
不偏分散:標本分散のバイアスを補正したもので、分母を n−1 とすることで、母分散の期待値と一致する。
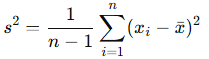
上の標本分散で分母を n-1 としたとき、
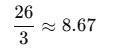
標準偏差(Standard Deviation)(不偏推定(Unbiased Variance))
標準偏差:分散の平方根。元のデータと同じ単位でばらつきを直感的に示します。
※下の式は母集団の場合
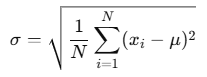
不偏推定:母集団の真の値(母数)を推定するとき、標本から計算した値に偏り(バイアス)がある場合があります。その偏りを補正して「平均的に正しい推定値」を得る方法を不偏推定といいます。
※標本分散は、母分散より小さめに出やすいので、分母を1引いて補正し「不偏分散」とします。標準偏差については、不偏分散の平方根を用いるのが一般的ですが、これは厳密な意味で不偏推定にはなりません。
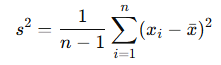
- 母分散 → (平方根)→ 母標準偏差(真の値)
- 標本分散 → (平方根)→ 標本標準偏差(標本の散らばり)
- 不偏分散 → (平方根)→ 不偏標準偏差(慣習的にそう呼ぶが厳密には不偏推定ではない)
| 種類 | 分母 | 分散 | 標準偏差 |
|---|---|---|---|
| 母標準偏差 | N=8 | 4.00 | 2.00 |
| 標本標準偏差 | n=8 | 6.50 | 2.55 |
| 不偏標準偏差 | n−1=7 | 8.67 | 2.94 |
平均絶対偏差(MAD around mean)
平均絶対偏差(MAD)は、データが平均からどのくらい離れているかを「絶対値」で測り、その平均をとったものです。
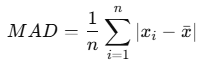

例:データ:2,4,4,4,5,5,7,9
平均 = 5
- 各偏差の絶対値:|2 – 5|,|4 – 5|,|4 – 5|,|4 – 5|,|5 – 5|,|5 – 5|,|7 – 5|,|9 – 5|
→3,1,1,1,0,0,2,4 - 合計 = 12
- 平均絶対偏差:12 / 8 = 1.5
四分位範囲(IQR)
四分位範囲(IQR)は、データを小さい順に並べて、下位25%の位置の値を第1四分位数(Q1)とし、下位75%の位置の値を第3四分位数(Q3)としたとき、IQR=Q3−Q1でデータの 真ん中50%がどのくらい広がっているか を示す指標です。
例:データ:2,4,4,4,5,5,7,9
- 並び替え済み(すでに昇順)
- Q1(下位25%の位置) = 4
- Q3(下位75%の位置) = 6(実際は5と7の間で 6)
- IQR = 6 − 4 = 2
👉 データの真ん中50%は「4から6の範囲」にある。
外れ値の検出には、次のようなルールが用いられます。
よく使われるルール:
- 外れ値の下限 = Q1 − 1.5 × IQR
- 外れ値の上限 = Q3 + 1.5 × IQR
👉 この範囲から外れる値を「外れ値」と判定することが多いです。
ロバストMAD(Median Absolute Deviation)
ロバストMADは中央値からのズレの中央値のことで、標準偏差や平均絶対偏差よりも外れ値の影響を受けにくいという特徴があります。これを利用して、データの外れ値の検索に利用されたりします。
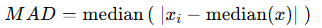
正規分布に基づく「ロバストな標準偏差の代替」として使う場合、次の補正係数(1.4826)を掛けます。
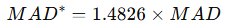
例:データ:2,4,4,4,5,5,7,9
- 中央値 = 4.5
- 各値との差の絶対値:2.5,0.5,0.5,0.5,0.5,0.5,2.5,4.5
- その中央値 = 0.5
👉 MAD = 0.5:標準偏差(≈2.0)と比べるとずっと小さく、外れ値に左右されにくいです。
変動係数(Coefficient of Variation, CV)
変動係数(CV)は、データの 平均に対する標準偏差の比率 を表す指標です。単位が違う指標の相対ばらつき比較に利用されます(平均が0付近だと不安定となります)。
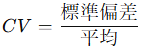

例:
データA: 平均 100, 標準偏差 10 → CVA=10/100=0.1=10%
データB: 平均 5, 標準偏差 2 → CVB=2/5=0.4=40%
👉 標準偏差だけ見ると A の方が大きいですが、CVで比較すると B の方が「相対的に散らばりが大きい」ことがわかります。
用途
- 異なる単位・スケールのデータ比較
例:売上(万円単位)と利益率(%)など - リスク評価(金融・投資)
投資リターンの平均に対して、どのくらいリスク(変動)があるかを見る - 測定の精度管理(工学・医療)
計測データの安定性を判断する基準として利用
範囲(Range)
範囲(Range)は、最大値と最小値の差でデータの広がりを表す最もシンプルな指標です。
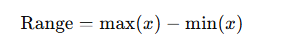
例:データ:2,4,4,4,5,5,7,9
Range = 9 − 2 = 7
特徴
- 計算が非常に簡単で直感的
- 外れ値に非常に弱い
- データの「端」しか見ていない
👉 実務では単体では使わず、IQRや標準偏差と併用するのが基本です。
形(分布の形状)
歪度(Skewness)
分布の左右非対称性を表す指標です。
- 正の歪み(右裾が長い)
- 平均 > 中央値
- 例:所得分布、売上分布
- 負の歪み(左裾が長い)
- 平均 < 中央値
特徴
- 外れ値の方向を把握できる
- 平均と中央値のズレの理由がわかる
👉 強い歪みがある場合:
- 対数変換
- Box-Cox変換
などを検討
尖度(Kurtosis)
分布の尖り具合・裾の重さを表します。
- レプトカート(尖っている・裾が重い)
- 外れ値が出やすい
- プラティカート(平たい)
- データが広く分散
※正規分布の尖度を基準(=3 or excess=0)として比較
特徴
- 外れ値の出やすさを示唆
- リスク分析(金融など)で重要
形状が大きく崩れていたら、平均+標準偏差だけの要約に頼らない(分位点や箱ひげ図も併用)。
分位点・百分位点(Quantiles/Percentiles)
分位点は、データを小さい順に並べたときの位置情報です。
- Q1(25%)
- Q2(50%)=中央値
- Q3(75%)
一般化すると:Qp:下から p% の位置。例:四分位 Q1,Q2(=median),Q3
実務でよく使う分位
- 90%点:上位10%の閾値
- 95%点:リスク管理
- 99%点:異常検知
90%・95% などの上位分位は、SLAや在庫バッファ設計に実務で有用。
活用例
- SLA(サービス品質)
- 「95%のリクエストは1秒以内」
- 在庫管理
- 「需要の95%をカバーする在庫量」
👉 平均よりも現実的な意思決定に強い
標準化とスケーリング
zスコア(標準化)
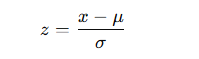
意味:平均から何標準偏差離れているか
特徴
- 単位を消せる
- 異なる指標を比較できる
- 多変量解析の前処理で必須
異なる単位の変数を比較/機械学習の前処理に。
外れ値に敏感(弱い) → 対策としてロバスト標準化(中央値とMAD)も選択肢。
最小最大スケーリング:0–1 に収めたいとき(ニューラルネットなど)
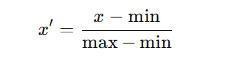
特徴
- 0〜1に収まる
- NNや距離ベース手法で有効
注意
- 外れ値の影響を強く受ける
標本 vs 母集団・標準誤差(SE)
標本統計量
- 標本平均
- 標本分散
👉 母集団を推定するための値
標準誤差(Standard Error)
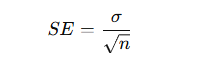
意味:
👉 「推定のブレ(不確かさ)」
特徴
- サンプル数が増えるほど小さくなる
- 推定の信頼性を示す
区間推定(Confidence Interval)
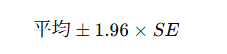
👉 「真の平均がこの範囲に入る確率が95%」
※厳密には:
「同じ手続きを繰り返したとき95%が当たる」
カテゴリ変数の基本統計量
度数・構成比
例:
- 男性:60%
- 女性:40%
最頻カテゴリ
最も多いカテゴリ(Mode)
エントロピー(Entropy)
カテゴリのばらつき・不確実性を表す指標
特徴
- 高い → バラバラ
- 低い → 偏っている
👉 マーケ・推薦システムで重要
グループ別集計・プーリング
グループ平均・分散
例:
- 店舗別売上
- 年代別購買額
👉 セグメント理解の基本
プールした分散(2群の例)
2つのグループの分散を統合:
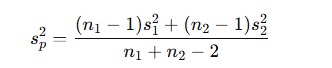
用途
- t検定
- 分散が等しいと仮定する場合

ブックマークのすすめ
「ほわほわぶろぐ」を常に検索するのが面倒だという方はブックマークをお勧めします。ブックマークの設定は別記事にて掲載しています。

仮説のタイプ分け-640x360.jpg)

クロス集計・カイ二乗検定-640x360.jpg)
準実験:傾向スコアマッチング(PSM)-640x360.jpg)
準実験:回帰不連続デザイン(RDD)-640x360.jpg)
-640x360.jpg)


重要用語-320x180.jpg)

多変量解析-320x180.jpg)
基本統計量-320x180.jpg)