データサイエンス(Part.20)|重要用語
重要用語-1280x720.jpg)
目標
基本統計量 信頼区間 決定係数 R² 相関係数 偏相関係数 残差平方和 RSS パネルデータ クロスセクションデータ 独立性の検定 残存効果 残差 相関行列 共分散 ダミー変数 重相関係数 調整済R² 予測値 実績値 過学習 CPR CPO CPA LTVについて整理する。
01 基本統計量
基本統計量は単なる要約ではなく、分析の前提条件チェックの役割を持っています。
実務で見るポイント
- 平均と中央値の乖離 → 歪みの存在
- 標準偏差が大きい → モデル難易度が高い
- IQRが狭い → 安定した分布
よくあるミス
- 平均だけ報告(→分布を無視)
- 標準偏差の単位を意識しない
02 信頼区間
信頼区間は「点」ではなく“幅”で判断するための道具です。
実務での重要な読み方
- 区間が0をまたぐ → 有意でない可能性
- 区間が狭い → 推定精度が高い
A/Bテストでの解釈
- 差があるか?(有意性)
- どのくらい違うか?(効果量)
👉 両方見る必要あり
03 決定係数(R²)
R²は「分散の説明割合」なので:👉 そもそも説明できない現象には限界がある
例:人間行動 → R²低くなりがち
実務での使い方
- モデル比較(同じデータ前提)
- 改善の進捗確認
注意(重要)
- 異なるデータでR²比較はNG
- 外れ値で簡単に上がることがある
04 相関係数
相関は「線形関係」しか見ていない
例:U字型 → 相関0でも関係あり
実務での補完
- 散布図を必ず確認
- スピアマン相関(順位)も検討
05 偏相関係数
偏相関は「条件付き関係」
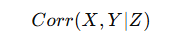
実務での価値:👉 多変量環境での“純粋効果”
限界
- 非線形は除去できない
- 因果までは保証しない
06 残差平方和(RSS)
OLSはこれを最小化する:👉 「最も平均的にズレが小さい線」
実務での発展
- RMSE(解釈しやすい)
- MAE(外れ値に強い)
注意
- 外れ値1つで大きく悪化
07パネルデータ
パネルデータは:👉 観測できないバイアスを制御できる
例:個人の能力・店舗の立地
実務で重要
- 固定効果 → 個体差除去
- 差分の差分(DID)→ 因果推論
08 クロスセクションデータ
弱点:👉 逆因果が判別できない
例:広告と売上(どっちが原因?)
09 独立性の検定
カイ二乗は:👉 期待値 vs 実測のズレ
実務での補足:標準化残差を見ると「どこが違うか」わかる
注意:サンプルが大きいと何でも有意になる
10 残存効果(残差)
理想の残差:平均0・ランダム・パターンなし
NGパターン:分散変化 → 不均一分散
👉 残差は「モデルの健康診断」
11 相関行列
高相関が問題なのは:👉 情報が重複しているから
実務:PCAで圧縮・片方削除
12 共分散
共分散は:👉 相関の“元の形”
使い所:PCA・多変量正規分布
13 ダミー変数
回帰式の意味:
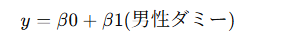
👉 β1 = 女性との差
実務で重要:基準カテゴリの設定
14 重相関係数・調整済R²
- R:予測と実測の相関
- R²:説明力
調整済R²の役割:👉 過学習の簡易チェック
15 予測値と実績値
分析の本質:👉 「どこでズレているか」
実務でやること
- 誤差の分布を見る
- セグメント別誤差
16 過学習
原因:モデルが複雑すぎる・データが少ない
兆候:学習精度 ↑・テスト精度 ↓
👉 「ノイズまで学習している」
19 CPR / CPO / CPA / LTV
CPR(反応単価)
深い意味:👉 興味関心の獲得効率
分解すると
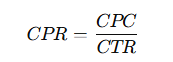
改善レバー:クリエイティブ・ターゲティング
CPO(注文単価)
分解
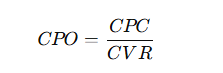
意味:👉 LPや導線の問題を反映
CPA(獲得単価)
本質:👉 ビジネスモデルに直結
分解
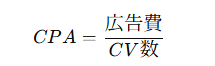
改善要因:ファネル全体最適化
LTV(顧客価値)
深掘り
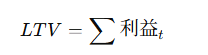
分解:単価・頻度・継続率
超重要:👉 継続率が最も効く
全体の関係(超重要)
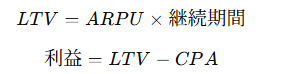
実務の意思決定
- ケース1:CPA 高い LTV 高い 👉 OK(投資すべき)
- ケース2:CPA 低い LTV 低い 👉 NG(質が悪い)
よくある重大ミス
- ① CPA最適化だけやる:👉 LTV悪化
- ② 短期指標だけ見る:👉 長期赤字
- ③ 平均LTVだけ見る:👉 セグメント無視
最重要:👉 「良い顧客をいくらで獲得できるか」

ブックマークのすすめ
「ほわほわぶろぐ」を常に検索するのが面倒だという方はブックマークをお勧めします。ブックマークの設定は別記事にて掲載しています。

基本統計量-640x360.jpg)
多変量解析-640x360.jpg)
カスタム調査とシンジケートデータ-640x360.png)
ロジスティック回帰・決定木-640x360.jpg)

クロス集計・カイ二乗検定-640x360.jpg)


重要用語-320x180.jpg)

多変量解析-320x180.jpg)
基本統計量-320x180.jpg)