データベース(Part.5)| 正規化 | 現役エンジニア&プログラミングスクール講師

目標
「正規化」について概要を理解して正規化を行える
正規化の概要と正規化の手順
正規化の概要
正規化とは
正規化とはデータベースをコンピューター上で扱いやすくするための設計手法(整理整頓のための手法)です。

正規化がなぜ必要か
正規化されていないデータベースではデータの更新時にデータの不整合が発生しやすくなります。このことを更新不整合(または更新時異常)といいます。

正規形の種類
正規化を行った後の状態を「正規形」と呼びます。正規形には次の種類があります。通常、正規形は第3正規形かボイス・コッド正規形までを目標とします。それ以上だと制約が強すぎてデメリットが増える傾向があります。
- 第1正規形
- 第2正規形
- 第3正規形
- ボイス・コッド正規形
- 第4正規形
- 第5正規形
重要用語の確認
タプル…データべースのレコード(行)のこと。
候補キー…タプルを一意に識別できる1つ以上の属性の集まり(主キーとしての候補)。
複合キー…複数の属性で構成される主キー。
非キー…どの候補キーにもならない通常の属性。
関数従属性…ある属性がきまると別の属性が決まること。
完全関数従属…複合キー全体に対して関数従属されていること。
部分関数従属…複合キーの一部の属性に対して関数従属されていること
取り除くことが必要(第2正規形)
推移的関数従属…属性がひとつ決まると「A→B→C」と順を追って関数従属が存在する状態
取り除くことが必要(第3正規形)
情報無損失分解…分解後の関連を自然結合できる(前の状態に戻すことができる)分解。
↔情報損失分解(結合の罠によって情報が戻らない)。
更新時異常…挿入時異常・削除時異常・修正時異常のことをいう。
正規化の手順
正規化の手順
正規化の手順は「非正規形」→「第1正規形」→「第2正規形」→「第3正規形」の順番で進んでいきます。
ここでは、おばあちゃんの駄菓子屋さんを例にデータベースの正規化を行っていこうと思います。ある日、近所の駄菓子屋のおばあちゃんからこんな事を頼まれたとします。

ねぇ、ねぇ、ほわほわ君、ちょっとお願いがあるんだよ。実は最近ね、お店の帳簿をつけるのに手が痛くてね、もっと管理が簡単にならないものかと思っていたんだけど、そこでほわほわ君が、でーたべーすってのを作れるって聞いたのよ。もしよかったら作ってくれないかねぇ?
ほわほわ君は、子供の頃からお世話になっているおばあちゃんの頼みなので快く引き受けました。そこで、おばあちゃんにこれまでの帳簿を見せてもらうことにしました。

おばあちゃん、分かりました。じゃ、どんな項目が必要かを確認しないといけないので、これまでの帳簿を参考までに見せてもらっていいですけ?
おばあちゃんから帳簿を預かって中身を確認すると次のようにノートにぎっしりと売り上げが書かれていました。

手渡された帳簿は正規化がされていない「非正規形」のデータベースということがほわほわ君にはすぐに分かりました。なので、ほわほわ君は正規化を行ってコンピューターが扱える状態を作り上げることにしました。
コンピューターにとってはこんな部分が苦手!

第1正規形
第1正規形の作成手順は次のようになります。
- 繰り返えしの項目を別々の行として編集する。
- 増えた行がもともと共通のものと分かるようにIDを振る。
- 切り離したテーブルが元のテーブルに一意に識別できる列をコピーする。
【繰り返えしの項目を別々の行として編集する。】
第1正規形を作成する最初の取り組みは「重複するフィールドをなくす」です。下のイラストにはデータベースのフィールド名「商品」「金額」「個数」が重複しているので、この重複をなくします。

まずはデータが繰り返して存在している行の下に1行追加します。

追加した行に上の行で繰り返し部分に表示されていたデータを移動してきます。この作業を繰り返えします。

全ての繰り返しのデータをひとつ目の「商品」「金額」「個数」に移動すると次のようになります。

【増えた行がもともと共通のものと分かるようにIDを振る。】
(行が増えていなくてもIDを振ります。下の図では0001や0009など)

【繰り返しで扱われていた部分を別のテーブルとして切り離す。】
下の赤枠部分を切り離します。

【切り離したテーブルが元のテーブルに一意に識別できる列をコピーする。】

以上で第1正規形が完成です。完成したテーブルは下のようになります。

目標の第2正規形
第2正規形の作成手順は次のようになります。
- データ部分に「同じものを指す」のに「表記が違う」ものがないかを探す。
- 表記を統一してデータを一意に認識できるようIDを付ける。
- 複合キーの一部に関数従属していれば切り離す。(部分関数従属の除去)
- 部分関数従属の決定項を主キーとする。
【データ部分に「同じものを指す」のに「表記が違う」ものがないかを探す。】
次の図のように表記がばらばらの状態ではコンピュータがうまくデータベースを扱うことができません。

【表記を統一してデータを一意に認識できるようIDを付ける。】

【複合キーの一部に関数従属していれば切り離す。(部分関数従属の除去)】
下の図を確認すると「個数」は複合キー(売上IDと商品IDの組み合わせ)で決まる値となります(完全関数従属)。
この時、複合キーのどちらかを主キーとして値が一意に決まるものがあれば、それが部分関数従属となります。下の図では「商品ID」が決まれば「商品」と「値段」が決まるといった部分にあたります。

「商品ID」「商品」「値段」の部分を切り離すと下の図のようになります。赤い枠の部分が切り離されたテーブルです。今後これを「商品テーブル」と呼びます。

【部分関数従属の決定項を主キーとする】
上の図の水色の部分を削除します。この時出来上がった「商品テーブル」では、部分関数従属の決定項(商品ID)が主キーとなります。
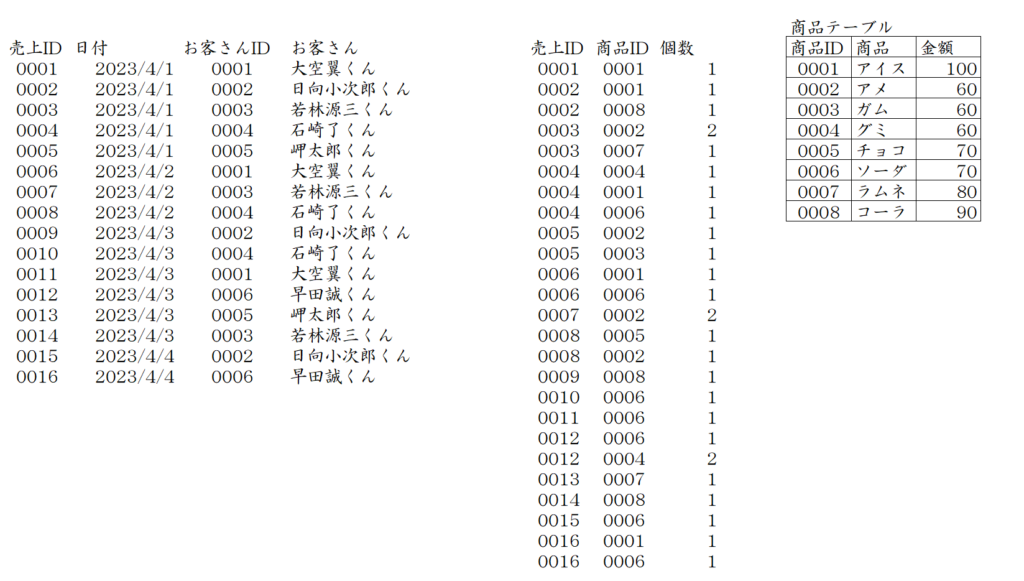
ここまでが、第2正規形のテーブル作成の手順です。
もう一つのテーブル(売上ID・お客さんID・お客さんのテーブル)を見てみるとこれは複合キーではなく「売上ID」が主キーとして利用されています。売上IDによって「お客さんID」や「お客さん」が決まる状態です。これは次の第3正規形を形成する時に考える推移的関数従属(推移関数従属)にあたります。

目標の第3正規形
第3正規形の作成手順は次のようになります。
- 主キーとなるもの(候補キー)を見つける。
- 非キー(どの候補キーにも含まれない属性)の中で関数従属がないかを確認。
- 非キー部分で関数従属していれば「推移的関数従属」となるので切り離す。
【主キーとなるもの(候補キー)を見つける。】

【非キー(どの候補キーにも含まれない属性)の中で関数従属がないかを確認。】
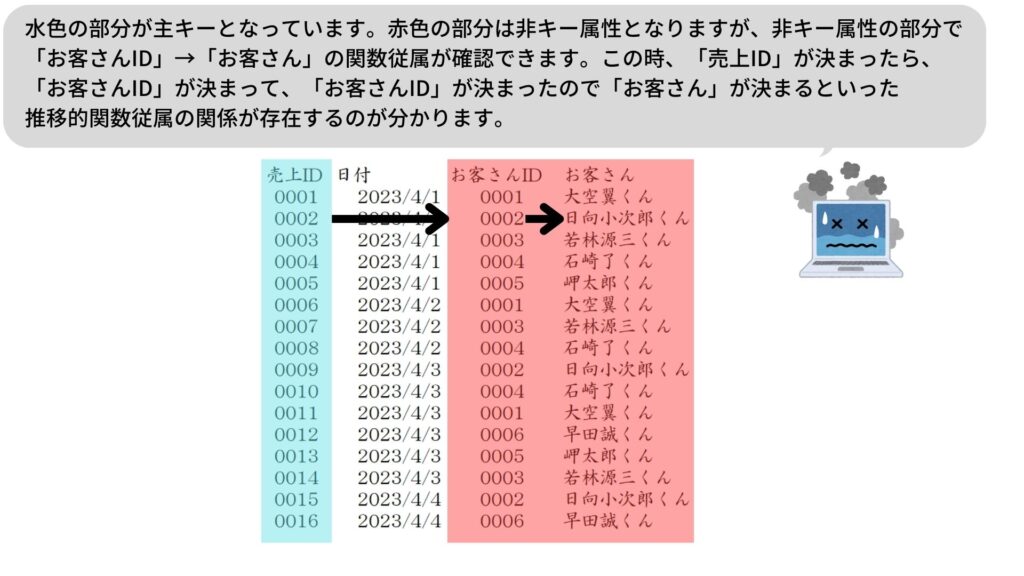
【非キー部分で関数従属していれば「推移的関数従属」となるので切り離す。】

ここまでで第3正規形のテーブルの作成は完了です。

今回は以上になります。次回以降はリレーションについて記事にしています。


ブックマークのすすめ
「ほわほわぶろぐ」を常に検索するのが面倒だという方はブックマークをお勧めします。ブックマークの設定は別記事にて掲載しています。




-640x360.jpg)




重要用語-320x180.jpg)

多変量解析-320x180.jpg)
基本統計量-320x180.jpg)